
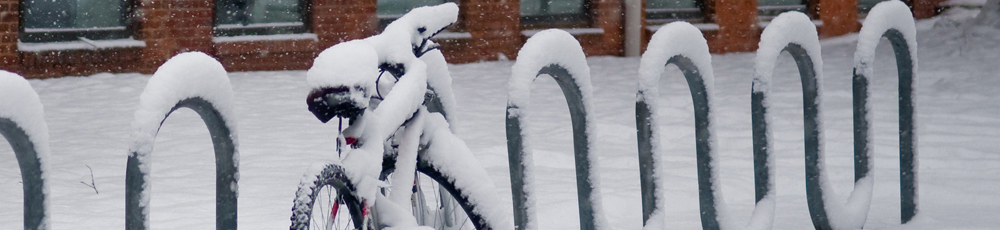
Another useful experimental paradigm is an Artificial Grammar Learning (AGL) task. This task aims to investigate the extent to which individuals can determine patterns when give a novel set of linguistic features generated by a certain rule. One such experiment might present individuals with sounds from a made-up language and then later ask them to judge individual items as part of that language or not. This task aims to determine the extent to which participants can figure out the underlying phonotactic constraints governing the input they received.
For this experiment we’ll be taking inspiration from an excellent youtube video by Kathryn Schuler, so if you’d prefer to watch the video (~30mins) you can find the link here.
Let’s suppose that our experiment consists of participants first being exposed to a short example of a fictional language following some sort of phonotactic constraints we’ve developed. After that, the test trial will begin and participants will hear novel words and be asked whether or not it’s from the “language” they just heard.
First, create the first instructions block as in previous examples, followed by a routine called “exposure”. In the exposure block, we’ll just have a single sound component. Since we have only one file, we won’t assign a variable to “Sound”, just give the file path to the single sound file and keep it at “constant”. We’d prefer in this example for the routine to end as soon as the sound file finishes playing. In order to do this, add a code component as below.

Figure 12 – End a routine automatically when the sound file ends
What the code does it checks every frame to see if the duration of the routine (defined as t) is greater than/equal to the duration of your sound component (don’t forget to change the name if yours isn’t “sound1”). If it has passed the duration, it ends the routine.
Then, create a second set of instructions as before, with text to the effect of “Your job is now to tell whether the words you hear are from the same language you just heard. Press “F” for yes and “J” for no.”
Finally, we’ll create the “test” routine where the participants will be judging words they hear. Add a polygon component running from 0-0.25 to ease with transitions. Then, add a sound component starting at 0.25 with a blank “Stop duration (s)” field. In the “Sound” field, add the variable $test_word and choose “Set every repeat”. Then, we’ll add a keyboard component to allow the participants to respond. It should look something like below.

Figure 13 – Keyboard response in “test” routine
Notice that we’ve set the “Start time (s)” to 0.25 (the end of the polygon) plus the duration of the sound component. You’ll have to change “sound_2” to the name of your component if it’s different. Also note that we’re only allowing keys ‘f’ and ‘j’, we’re Storing correct/incorrect, and we’re making those judgments based on the variable $correctAns. Now we’ll create the conditions file as below and use it to loop our “test” routine.
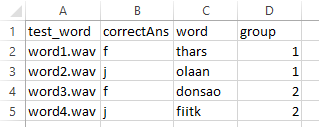
Figure 14 – AGL conditions file
Note that I’ve also added extra information in the “word” and “group” columns. This meta-data will not be used to run the experiment, but will be helpfully stored in the data output by PsychoPy. Your flow panel should look something like below. Once you’ve tested the structure, begin editing it for your own purposes.

Figure 15 – AGL Flow Panel
Back to (4. PyschoPy Tutorial: Conditional branching)